Ollama+openwebui
安装ollama
curl -fsSL https://ollama.com/install.sh | sh
运行ollama
export OLLAMA_HOST=0.0.0.0
ollama serve
(base) root@c2e882693a43eed7fcb13a3df6d29cb7-taskrole1-0:~# ollama serve
time=2024-04-09T13:31:56.306+08:00 level=INFO source=images.go:804 msg="total blobs: 18"
time=2024-04-09T13:31:56.307+08:00 level=INFO source=images.go:811 msg="total unused blobs removed: 0"
time=2024-04-09T13:31:56.307+08:00 level=INFO source=routes.go:1118 msg="Listening on 127.0.0.1:11434 (version 0.1.30)"
time=2024-04-09T13:31:56.357+08:00 level=INFO source=payload_common.go:113 msg="Extracting dynamic libraries to /tmp/ollama1127788686/runners ..."
time=2024-04-09T13:31:59.767+08:00 level=INFO source=payload_common.go:140 msg="Dynamic LLM libraries [rocm_v60000 cuda_v11 cpu_avx2 cpu_avx cpu]"
time=2024-04-09T13:31:59.767+08:00 level=INFO source=gpu.go:115 msg="Detecting GPU type"
time=2024-04-09T13:31:59.767+08:00 level=INFO source=gpu.go:265 msg="Searching for GPU management library libcudart.so*"
time=2024-04-09T13:31:59.769+08:00 level=INFO source=gpu.go:311 msg="Discovered GPU libraries: [/tmp/ollama1127788686/runners/cuda_v11/libcudart.so.11.0 /usr/local/cuda/lib64/libcudart.so.12.1.55]"
time=2024-04-09T13:31:59.931+08:00 level=INFO source=gpu.go:120 msg="Nvidia GPU detected via cudart"
time=2024-04-09T13:31:59.931+08:00 level=INFO source=cpu_common.go:11 msg="CPU has AVX2"
time=2024-04-09T13:32:00.308+08:00 level=INFO source=gpu.go:188 msg="[cudart] CUDART CUDA Compute Capability detected: 8.6"
^C(base) root@c2e882693a43eed7fcb13a3df6d29cb7-taskrole1-0:~#
(base) root@c2e882693a43eed7fcb13a3df6d29cb7-taskrole1-0:~#
(base) root@c2e882693a43eed7fcb13a3df6d29cb7-taskrole1-0:~# export OLLAMA_HOST=0.0.0.0
(base) root@c2e882693a43eed7fcb13a3df6d29cb7-taskrole1-0:~# ollama serve
time=2024-04-09T13:34:34.936+08:00 level=INFO source=images.go:804 msg="total blobs: 18"
time=2024-04-09T13:34:34.937+08:00 level=INFO source=images.go:811 msg="total unused blobs removed: 0"
time=2024-04-09T13:34:34.937+08:00 level=INFO source=routes.go:1118 msg="Listening on [::]:11434 (version 0.1.30)"
time=2024-04-09T13:34:34.939+08:00 level=INFO source=payload_common.go:113 msg="Extracting dynamic libraries to /tmp/ollama1531663222/runners ..."
time=2024-04-09T13:34:38.387+08:00 level=INFO source=payload_common.go:140 msg="Dynamic LLM libraries [cpu_avx2 rocm_v60000 cuda_v11 cpu cpu_avx]"
time=2024-04-09T13:34:38.387+08:00 level=INFO source=gpu.go:115 msg="Detecting GPU type"
time=2024-04-09T13:34:38.387+08:00 level=INFO source=gpu.go:265 msg="Searching for GPU management library libcudart.so*"
time=2024-04-09T13:34:38.389+08:00 level=INFO source=gpu.go:311 msg="Discovered GPU libraries: [/tmp/ollama1531663222/runners/cuda_v11/libcudart.so.11.0 /usr/local/cuda/lib64/libcudart.so.12.1.55]"
time=2024-04-09T13:34:38.539+08:00 level=INFO source=gpu.go:120 msg="Nvidia GPU detected via cudart"
time=2024-04-09T13:34:38.539+08:00 level=INFO source=cpu_common.go:11 msg="CPU has AVX2"
time=2024-04-09T13:34:38.910+08:00 level=INFO source=gpu.go:188 msg="[cudart] CUDART CUDA Compute Capability detected: 8.6"
[GIN] 2024/04/09 - 13:34:42 | 200 | 100.456µs | 10.2.170.115 | GET "/"
[GIN] 2024/04/09 - 13:34:42 | 404 | 18.205µs | 10.2.170.115 | GET "/favicon.ico"
[GIN] 2024/04/09 - 13:34:44 | 200 | 32.386µs | 10.2.170.115 | GET "/"
[GIN] 2024/04/09 - 13:35:50 | 200 | 59.039µs | 127.0.0.1 | HEAD "/"
[GIN] 2024/04/09 - 13:35:50 | 200 | 1.774928ms | 127.0.0.1 | POST "/api/show"
[GIN] 2024/04/09 - 13:35:50 | 200 | 1.215644ms | 127.0.0.1 | POST "/api/show"
time=2024-04-09T13:35:50.620+08:00 level=INFO source=cpu_common.go:11 msg="CPU has AVX2"
time=2024-04-09T13:35:50.621+08:00 level=INFO source=gpu.go:188 msg="[cudart] CUDART CUDA Compute Capability detected: 8.6"
time=2024-04-09T13:35:50.621+08:00 level=INFO source=cpu_common.go:11 msg="CPU has AVX2"
time=2024-04-09T13:35:50.622+08:00 level=INFO source=gpu.go:188 msg="[cudart] CUDART CUDA Compute Capability detected: 8.6"
time=2024-04-09T13:35:50.622+08:00 level=INFO source=cpu_common.go:11 msg="CPU has AVX2"
loading library /tmp/ollama1531663222/runners/cuda_v11/libext_server.so
time=2024-04-09T13:35:51.108+08:00 level=INFO source=dyn_ext_server.go:87 msg="Loading Dynamic llm server: /tmp/ollama1531663222/runners/cuda_v11/libext_server.so"
time=2024-04-09T13:35:51.108+08:00 level=INFO source=dyn_ext_server.go:147 msg="Initializing llama server"
{"function":"load_model","level":"INFO","line":391,"msg":"Multi Modal Mode Enabled","tid":"140300055992064","timestamp":1712640951}
clip_model_load: model name: openai/clip-vit-large-patch14-336
clip_model_load: description: image encoder for LLaVA
clip_model_load: GGUF version: 3
clip_model_load: alignment: 32
clip_model_load: n_tensors: 377
clip_model_load: n_kv: 19
clip_model_load: ftype: f16
clip_model_load: loaded meta data with 19 key-value pairs and 377 tensors from /root/.ollama/models/blobs/sha256-72d6f08a42f656d36b356dbe0920675899a99ce21192fd66266fb7d82ed07539
clip_model_load: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
clip_model_load: - kv 0: general.architecture str = clip
clip_model_load: - kv 1: clip.has_text_encoder bool = false
clip_model_load: - kv 2: clip.has_vision_encoder bool = true
clip_model_load: - kv 3: clip.has_llava_projector bool = true
clip_model_load: - kv 4: general.file_type u32 = 1
clip_model_load: - kv 5: general.name str = openai/clip-vit-large-patch14-336
clip_model_load: - kv 6: general.description str = image encoder for LLaVA
clip_model_load: - kv 7: clip.projector_type str = mlp
clip_model_load: - kv 8: clip.vision.image_size u32 = 336
clip_model_load: - kv 9: clip.vision.patch_size u32 = 14
clip_model_load: - kv 10: clip.vision.embedding_length u32 = 1024
clip_model_load: - kv 11: clip.vision.feed_forward_length u32 = 4096
clip_model_load: - kv 12: clip.vision.projection_dim u32 = 768
clip_model_load: - kv 13: clip.vision.attention.head_count u32 = 16
clip_model_load: - kv 14: clip.vision.attention.layer_norm_epsilon f32 = 0.000010
clip_model_load: - kv 15: clip.vision.block_count u32 = 23
clip_model_load: - kv 16: clip.vision.image_mean arr[f32,3] = [0.481455, 0.457828, 0.408211]
clip_model_load: - kv 17: clip.vision.image_std arr[f32,3] = [0.268630, 0.261303, 0.275777]
clip_model_load: - kv 18: clip.use_gelu bool = false
clip_model_load: - type f32: 235 tensors
clip_model_load: - type f16: 142 tensors
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: yes
ggml_cuda_init: CUDA_USE_TENSOR_CORES: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA A40, compute capability 8.6, VMM: yes
clip_model_load: CLIP using CUDA backend
clip_model_load: text_encoder: 0
clip_model_load: vision_encoder: 1
clip_model_load: llava_projector: 1
clip_model_load: model size: 595.49 MB
clip_model_load: metadata size: 0.14 MB
clip_model_load: params backend buffer size = 595.49 MB (377 tensors)
key clip.vision.image_grid_pinpoints not found in file
key clip.vision.mm_patch_merge_type not found in file
key clip.vision.image_crop_resolution not found in file
clip_model_load: compute allocated memory: 32.89 MB
llama_model_loader: loaded meta data with 24 key-value pairs and 291 tensors from /root/.ollama/models/blobs/sha256-170370233dd5c5415250a2ecd5c71586352850729062ccef1496385647293868 (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = liuhaotian
llama_model_loader: - kv 2: llama.context_length u32 = 32768
llama_model_loader: - kv 3: llama.embedding_length u32 = 4096
llama_model_loader: - kv 4: llama.block_count u32 = 32
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 14336
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 8
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 10: llama.rope.freq_base f32 = 1000000.000000
llama_model_loader: - kv 11: general.file_type u32 = 2
llama_model_loader: - kv 12: tokenizer.ggml.model str = llama
运行llava模型
ollama run gemma:2b
API调用
curl http://localhost:11434/api/chat -d '{
> "model": "gemma:2b",
> "messages": [
> { "role": "user", "content": "为什么天空是蓝的?" }
> ]
> }'
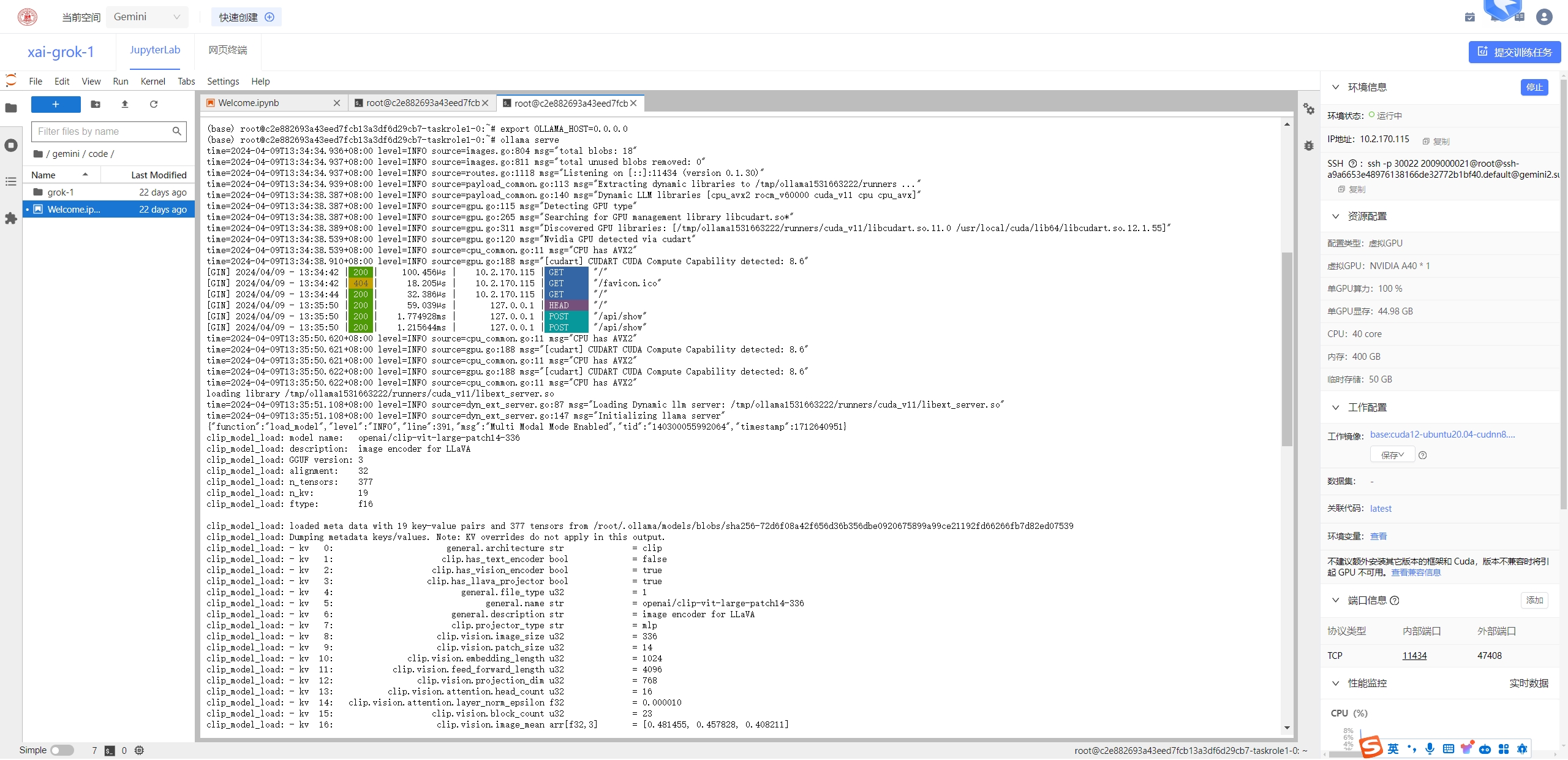
配置openwebui调用ollama
docker run -d -p 5000:8080 -e OLLAMA_API_BASE_URL=http://10.2.168.77:11434/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
其中OLLAMA_API_BASE_URL写自己的ollama的地址
- 打开openwebui的界面,http://10.2.168.77:5000/
第一次要设置账户和密码,然后登录
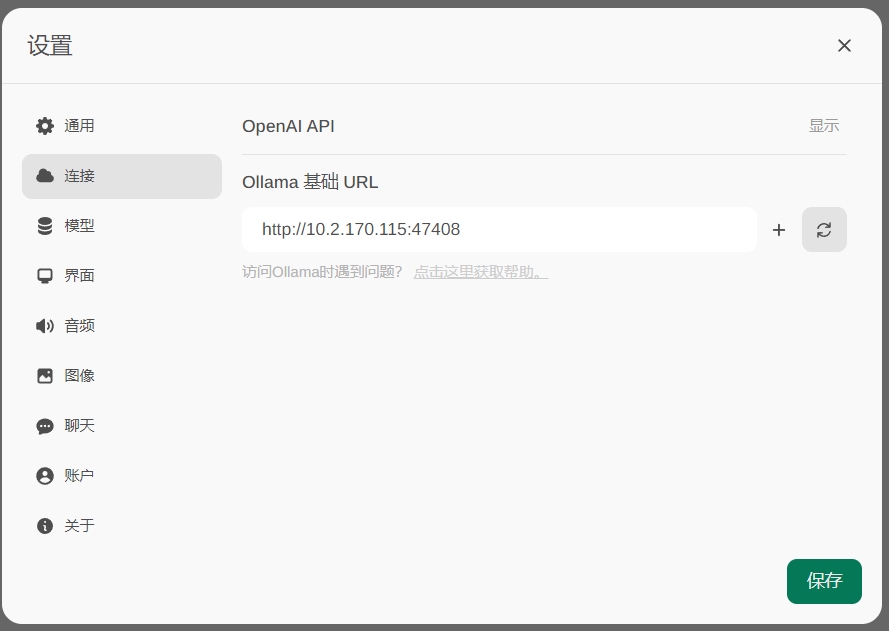
- 配置一下ollama的模型
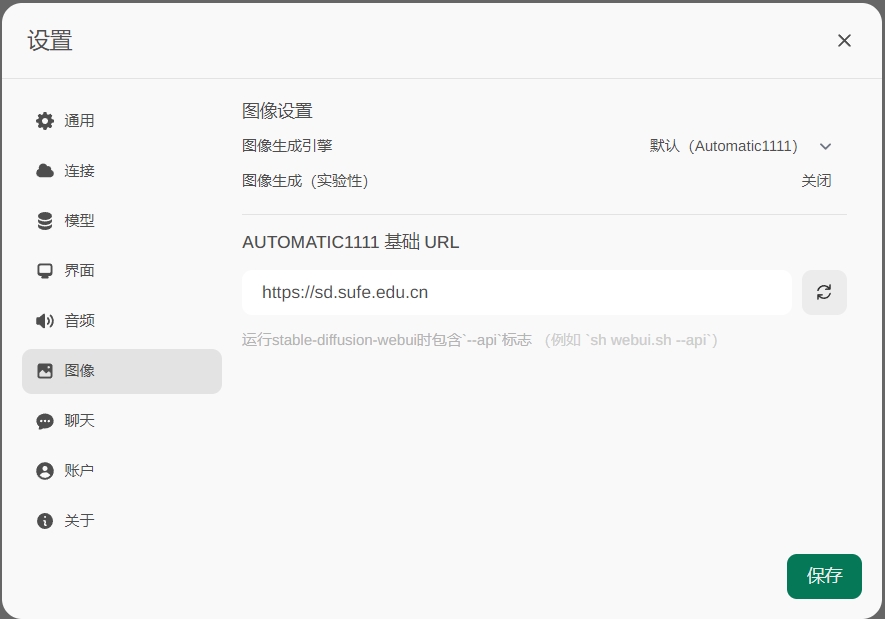
- 如果有stable-diffusion-webui也可以配置一下
- 我的ollama上已经跑了一个llava7B的模型和gemma、qwen
- 我们测试一下llava模型的图片能力
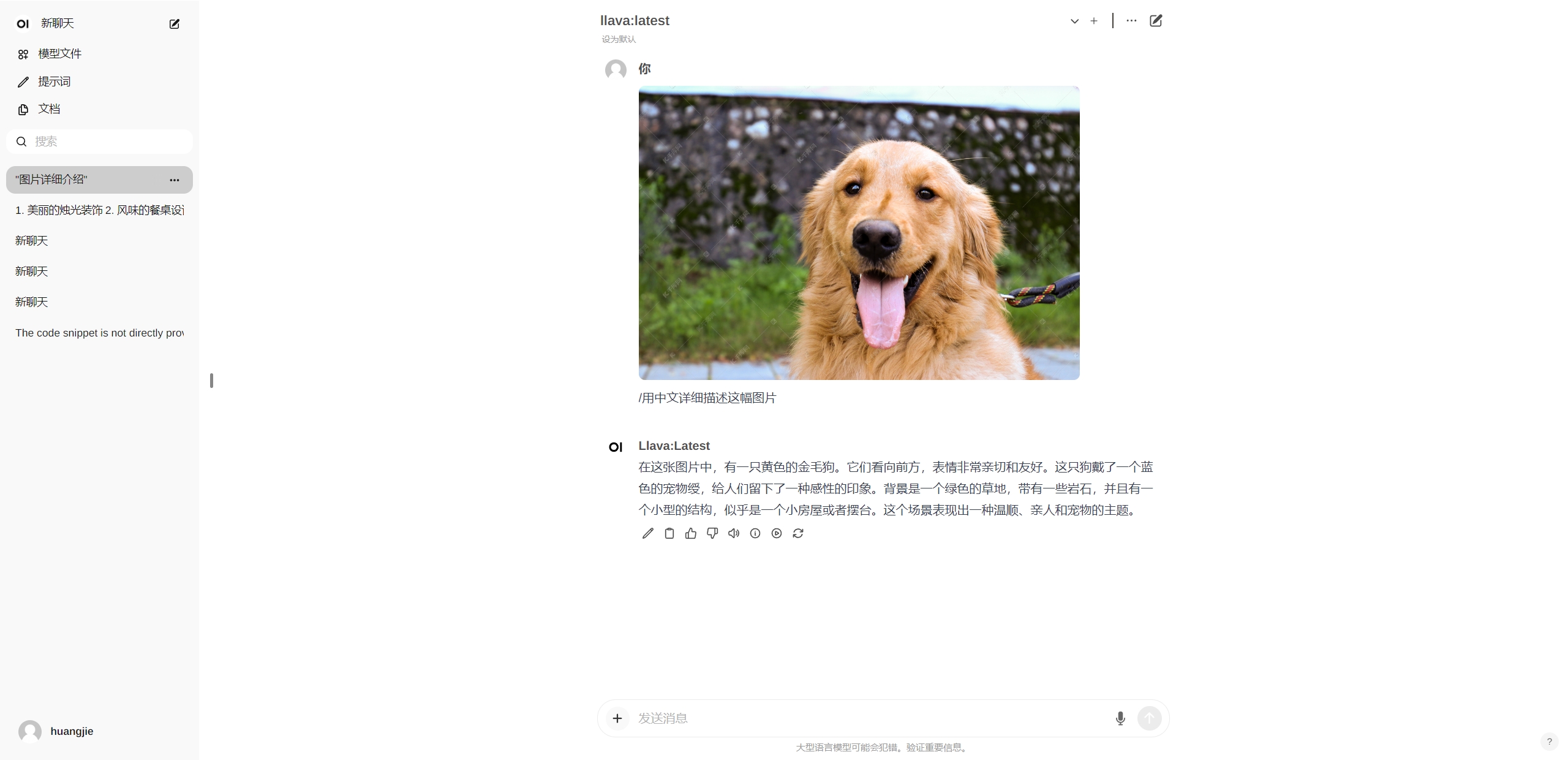
效果非常的不错哦!