多机多卡分布式训练之DeepSpeed
前言
支持LLM分布式训练的框架很多,有Megatron、DeepSpeed、Accelerate、FairScale等等。
Megatron是由NVIDI 深度学习应用研究团队开发的大型Transformer语言模型,该模型用于研究大规模训练大型语言模型。
DeepSpeed是由Microsoft提供的分布式训练工具。
Accelerate是PyTorch官方提供的分布式训练工具。
FairScale由Facebook提供的,是一个用于高性能和大规模训练的PyTorch扩展库。
推荐使用DeepSpeed
支持更大规模的模型
提供了更多的优化策略和工具,例如ZeRO和Offload等。
目前主流的组合方式:PyTorch + GPU + DeepSpeed + LLM训练框架
DeepSpeed的优势
存储效率:DeepSpeed提供了一种Zero的新型解决方案来减少训练显存的占用,它与传统的数据并行不同,它将模型状态和梯度进行分区来节省大量的显存
可扩展性:DeepSpeed支持高效的数据并行、模型并行、pipeline并行以及它们的组合,这里也称3D并行
易用性: 在训练阶段,只需要修改几行代码就可以使pytorch模型使用DeepSpeed。
登录上财人工智能平台
登录上财教学网https://bb.sufe.edu.cn,选择“算力与实验”--“人工智能平台”进入平台
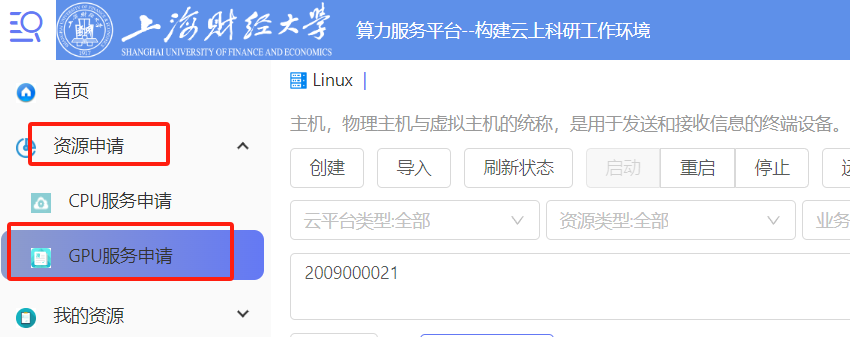
选择GPU服务申请,自动跳转到gemini平台
新建项目并初始化开发环境
代码仓库信息:
https://github.com/baichuan-inc/Baichuan2.git
分支:main
镜像选择:公开镜像 huangjie:Baichuan2-13B
数据挂载:公开数据集 Baichuan2-13B-Chat


拉取最新的baichuan2的代码仓库
在拉取的过程中,由于github网络不稳定,可能导致拉取仓库失败,多试几次。
安装一些依赖包,安装过程大概需要五六分钟
cd /gemini/code
git clone https://github.com/baichuan-inc/Baichuan2.git
cd /gemini/code/Baichuan2
pip install -r requirements.txt
cd fine-tune
pip install -r requirements.txt

打开web管理端,注意要把内部端口7860映射到外部端口,而且要找到自己的运行项目的ip地址,我的项目中的ip地址是:10.2.170.120,我的外部端口是49542
校内访问链接:http://10.2.170.120:49542/
- 注意,学生使用sufe的三大运营商的网络时,需要使用学校网信中心提供的VPN服务,否则有可能网络不可达
微调参数配置
参考文献
参考文献:https://huggingface.co/docs/transformers/main/zh/main_classes/deepspeed
DeepSpeed官网:https://github.com/microsoft/DeepSpeed
参考文献:https://blog.csdn.net/weixin_43646592/article/details/134713912