小白也能微调大模型(LLM Fine-Tuning)
前言
大模型火了之后,相信不少同学都在尝试将预训练大模型应用到自己的场景上,希望得到一个垂类专家,而不是通用大模型。
有监督微调,用适量的专业领域的数据让模型更能生成目标场景的内容。本文主要讲的就是微调。
什么是LLaMA-Factory
- 要做大模型的微调,需要以下几个条件
首选要有GPU算力,上财AI平台,提供了免费的算力,全校师生共享使用
一个强大的大模型微调框架,最好有webui零代码微调大模型,这就是LLaMA Factory的作用了
LLaMA-Factory的特色
多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练和 ORPO 训练。
多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
先进算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 Agent 微调。
实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
登录上财人工智能平台
登录上财教学网https://bb.sufe.edu.cn,选择“算力与实验”--“人工智能平台”进入平台
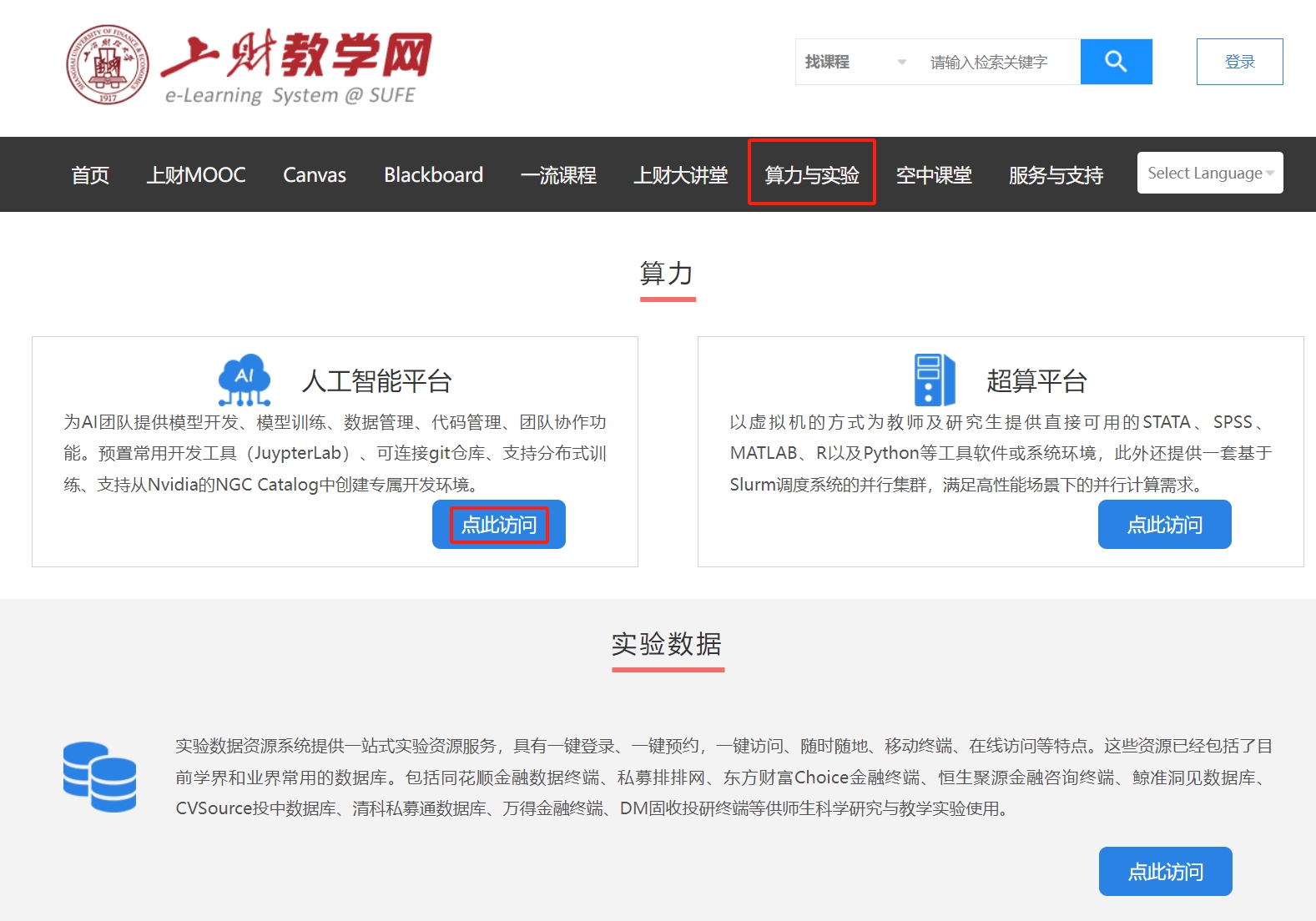
选择GPU服务申请,自动跳转到gemini平台
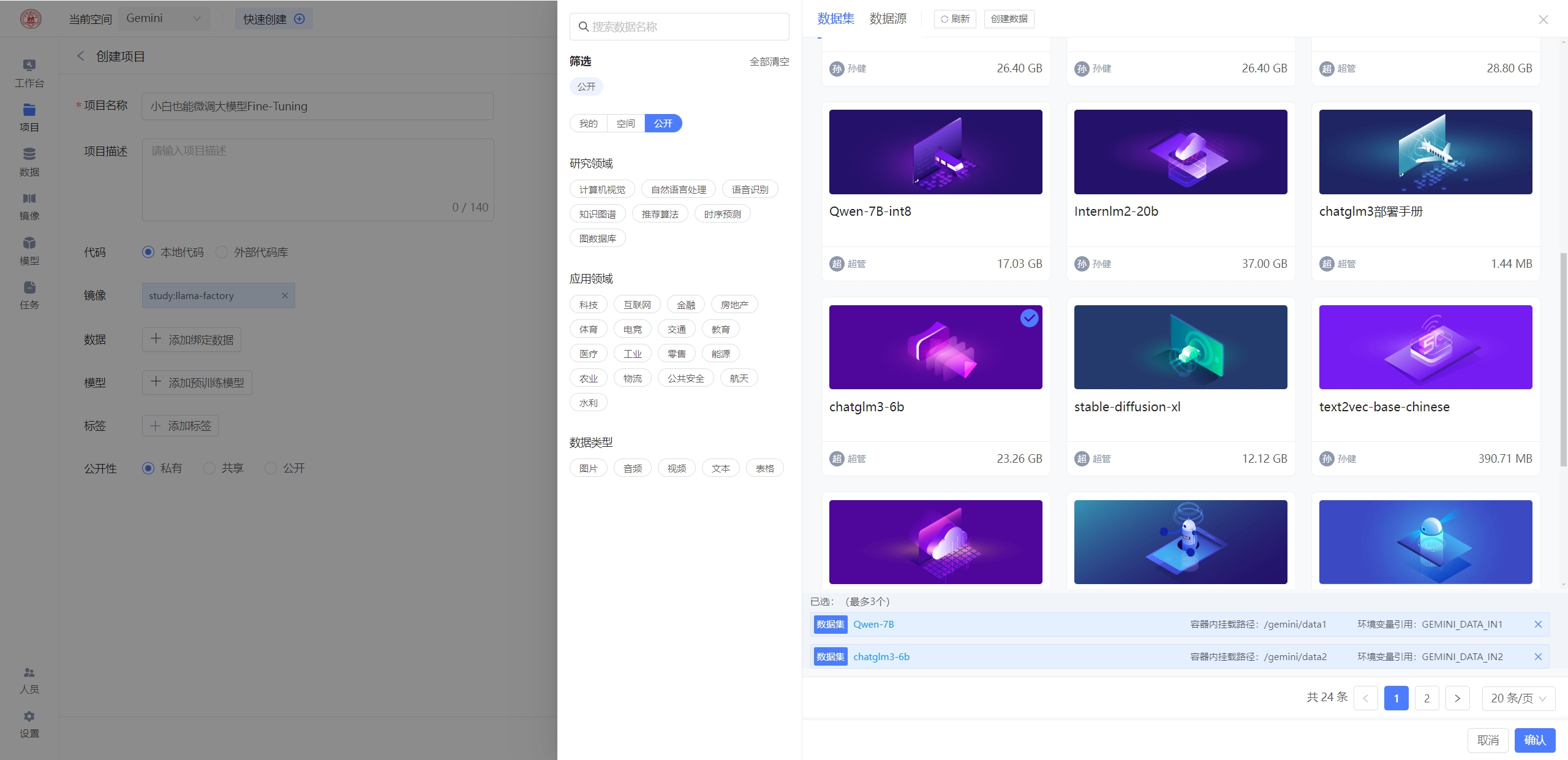
新建项目
代码仓库信息:
https://github.com/hiyouga/LLaMA-Factory.git
分支:main
镜像选择:公开镜像 study:llama-factory
数据挂载:公开数据集 chatglm3-6b-chat和Qwen-7B-chat
此处挂载两个模型,分别是chatglm3-6b-chat和Qwen-7B-chat的模型,主要是便于后面微调时对比不同模型的微调效果
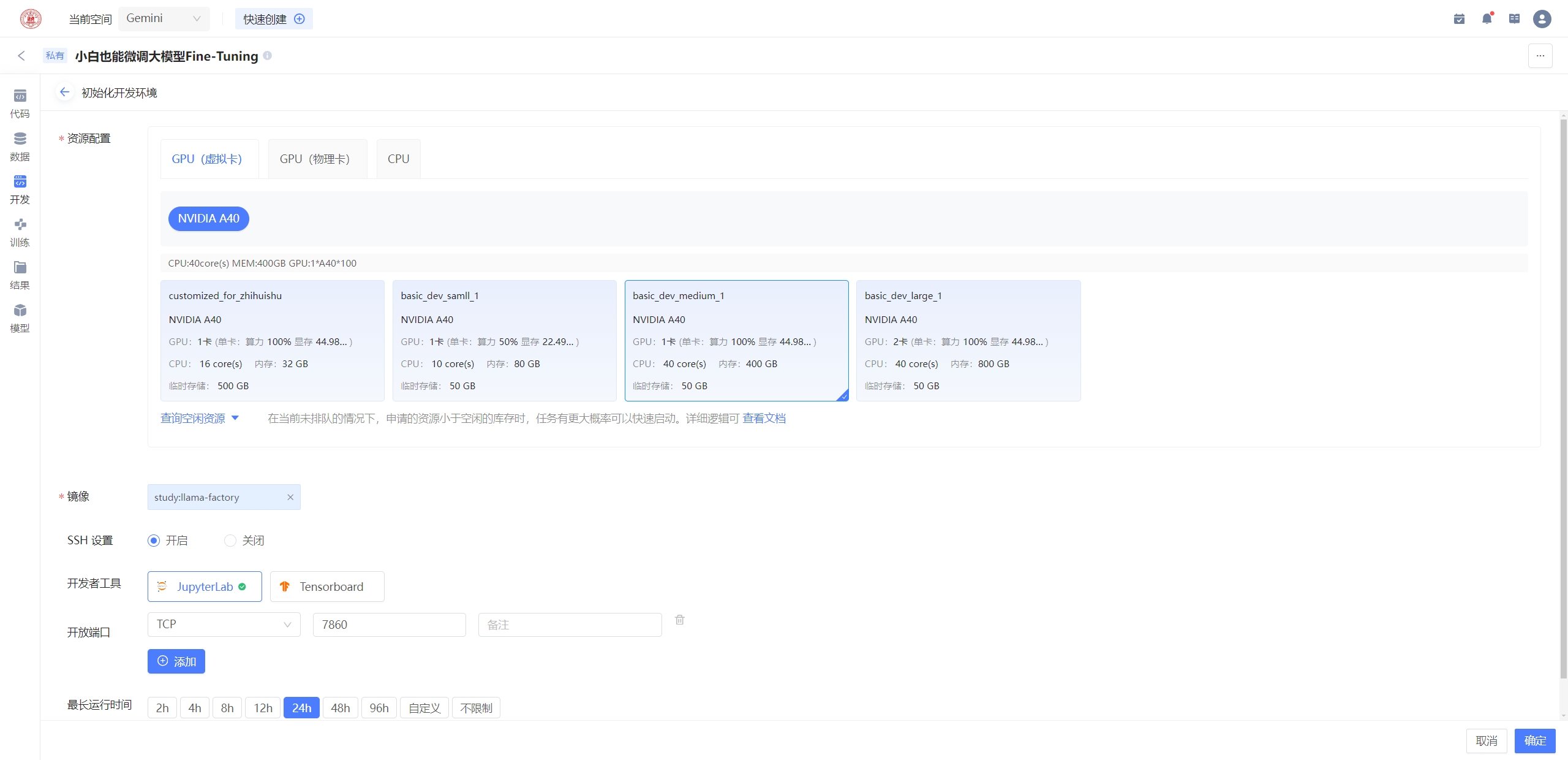
运行llama-factory
bash start.sh

打开web管理端,注意要把内部端口7860映射到外部端口,而且要找到自己的运行项目的ip地址,我的项目中的ip地址是:10.2.170.120,我的外部端口是49542
校内访问链接:http://10.2.170.120:49542/
- 注意,学生使用sufe的三大运营商的网络时,需要使用学校网信中心提供的VPN服务,否则有可能网络不可达
微调参数配置
- 根据需要,调整一些初始化的参数配置,不会调整的可以参考下图,简单的微调一下,看看效果。将微调结果保存到/gemini/code目录,做持久保存。
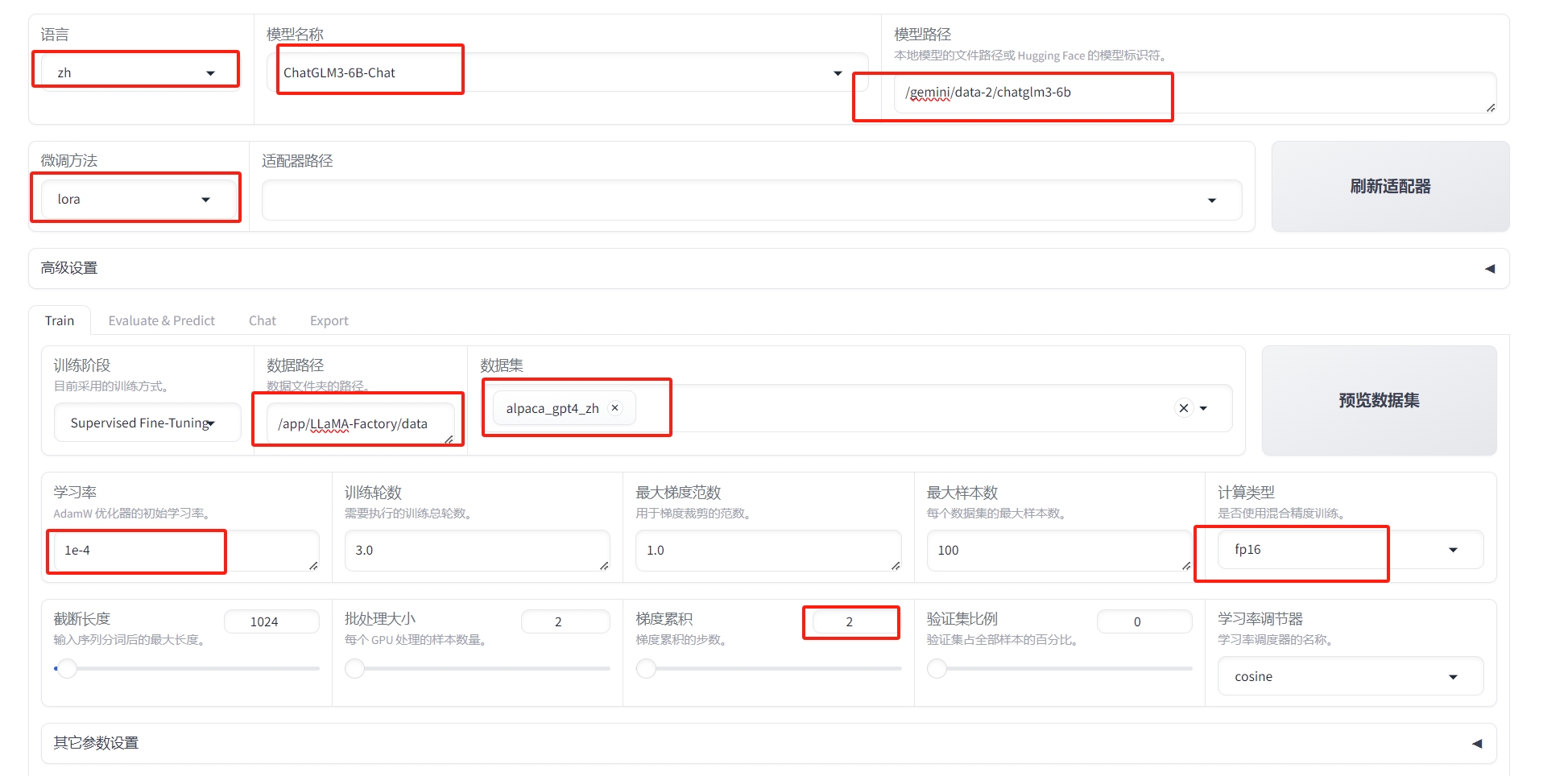

建议参数
| 参数 | 建议取值 | 说明 |
|---|---|---|
| 模型名称 | ChatGLM3-6B-Chat | 模型名称 |
| 微调方法 | lora | 使用LoRA轻量化微调方法能在很大程度上节约显存 |
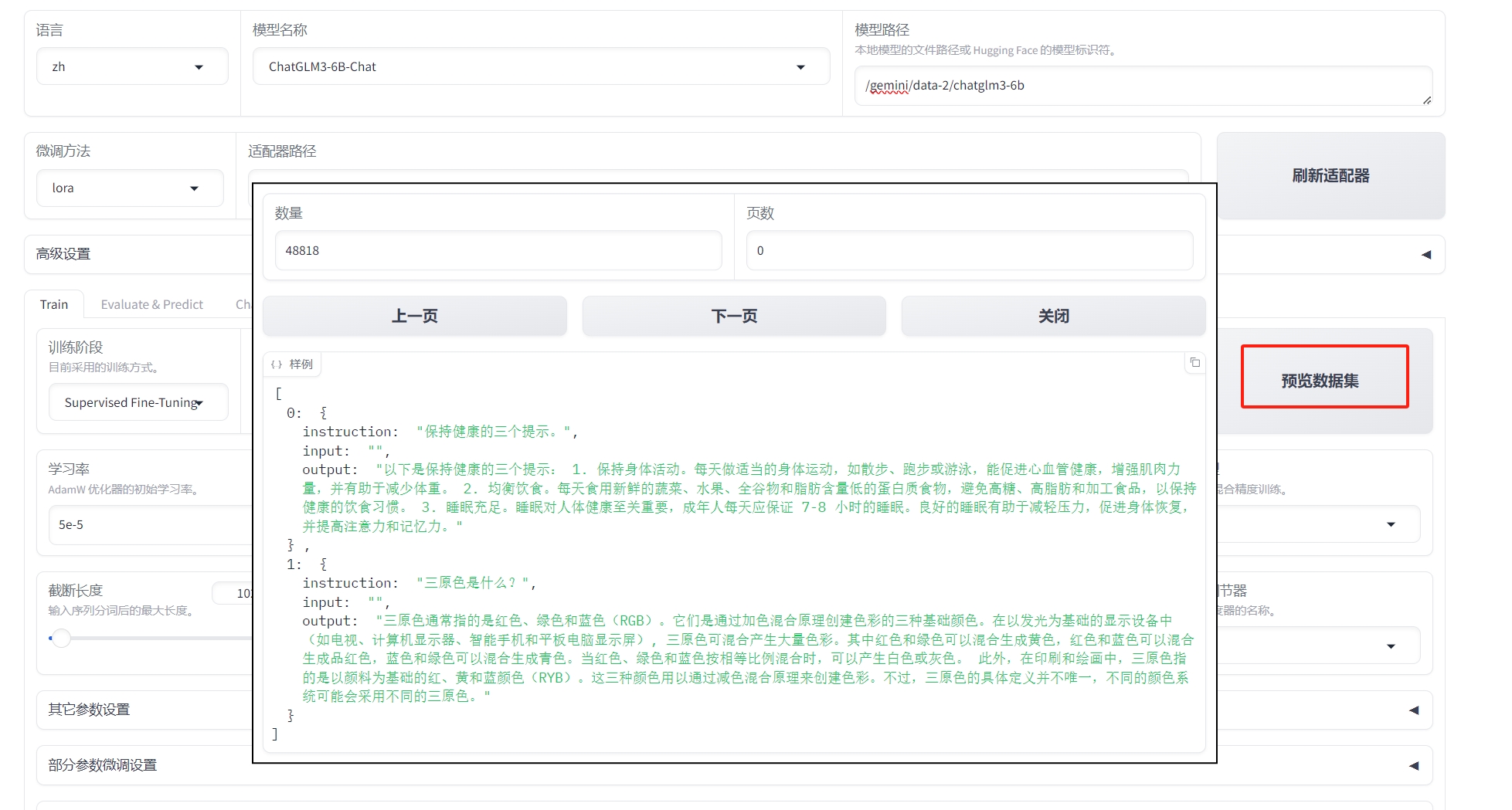
| 数据集 | alpaca_gpt4_zh | 择数据集后,可以单击预览数据集查看数据集详情 |
| 学习率 | 1e-4 | 有利于模型拟合 |
| 计算类型 | fp16 | A40显卡建议选择半精度fp16 |
| 梯度累计 | 2 | 有利于模型拟合 |
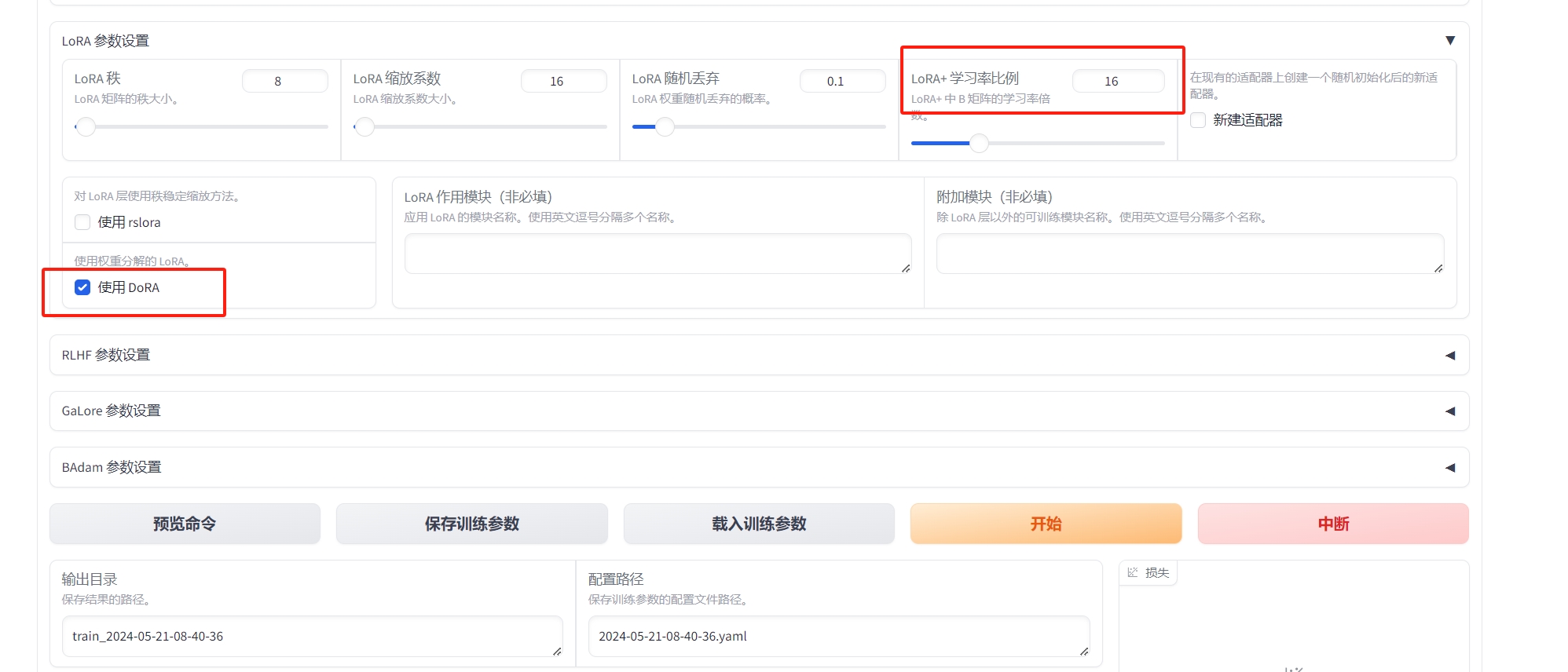
| LoRA+学习率比例 | 16 | 相比LoRA,LoRA+续写效果更好 |
| LoRA作用模块 | all | all表示将LoRA层挂载到模型的所有线性层上,提高拟合效果 |
- 参数配置好了之后,点击开始训练,微调开始进行,页面会打印微调日志输出。微调完成后,会出现右侧的loss曲线图。

- 稍等几分钟,训练完成(这里为了demo的效果,选择的数据量比较少,所以单卡A40,训练的很快)
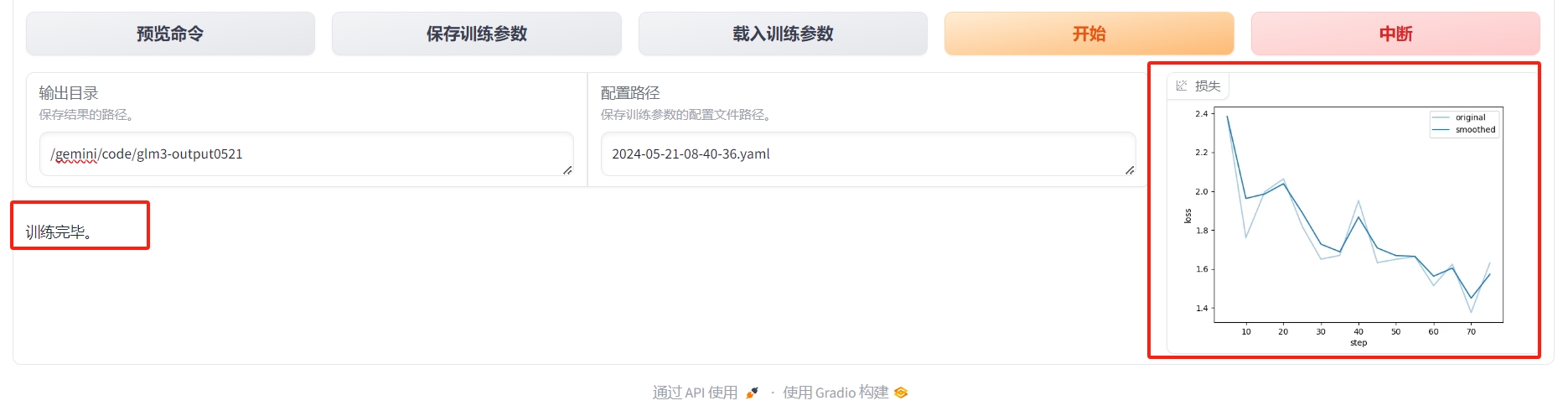
模型验证
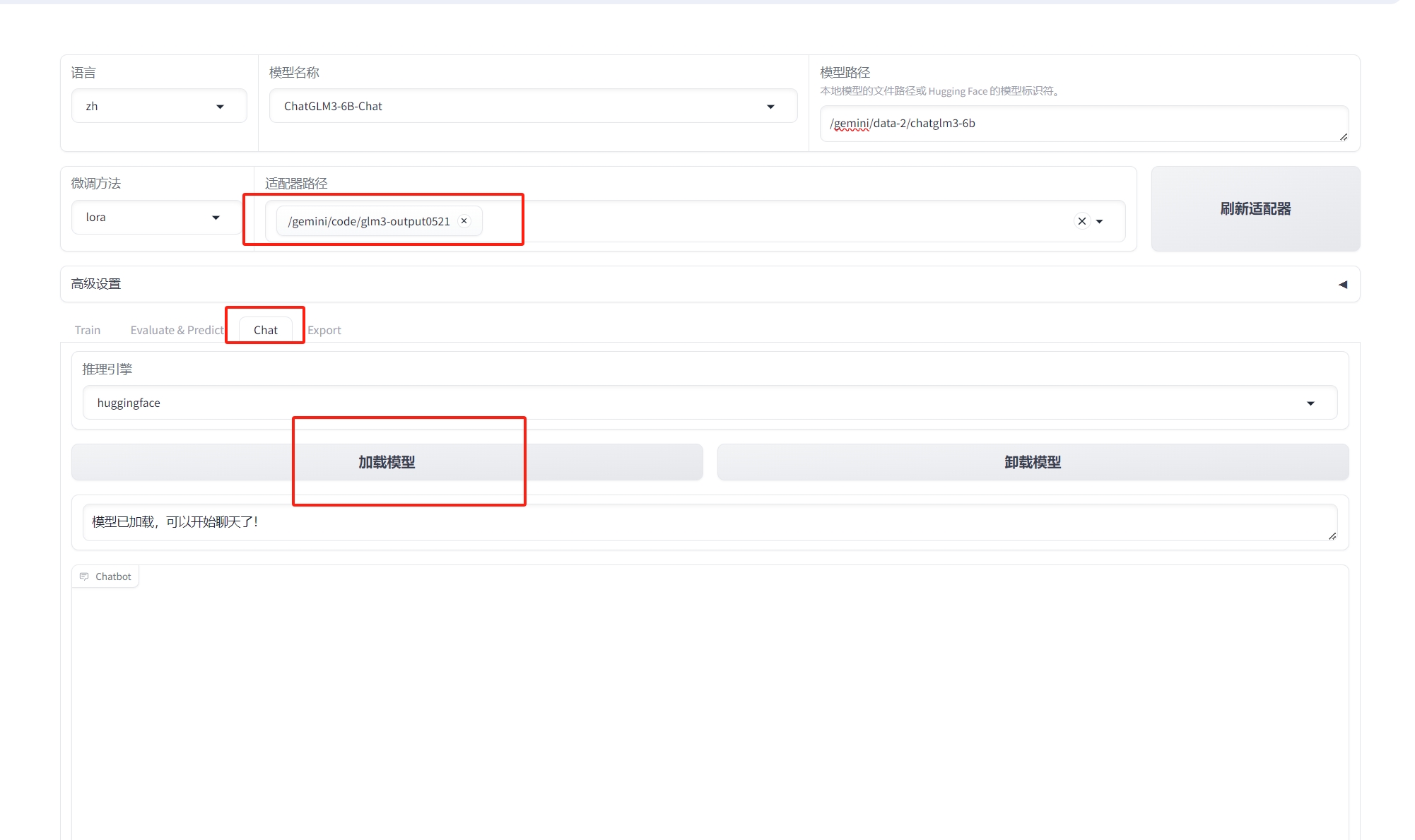
- 点击chat,加载模型,验证一下训练的效果
参考文献
如果需要自定义数据集,可以需要修改data/dataset_info.json文件,具体可以参考https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md
微调方法参考链接:https://blog.csdn.net/m0_69655483/article/details/137056646
项目参考文档:https://help.aliyun.com/zh/pai/use-cases/fine-tune-a-llama-3-model-with-llama-factory
llama-factory webui方式微调,目前只支持单卡微调