【个人独享】10分钟手搓一个DeepSeek-R1
上海财经大学师生们,想拥有个人独享版的DeepSeek-R1吗,那就赶紧花十分钟手搓一个吧,免费的独立的运行在上财AI平台上
登录上财人工智能平台
登录上财教学网https://bb.sufe.edu.cn,选择“算力与实验”--“人工智能平台”进入平台
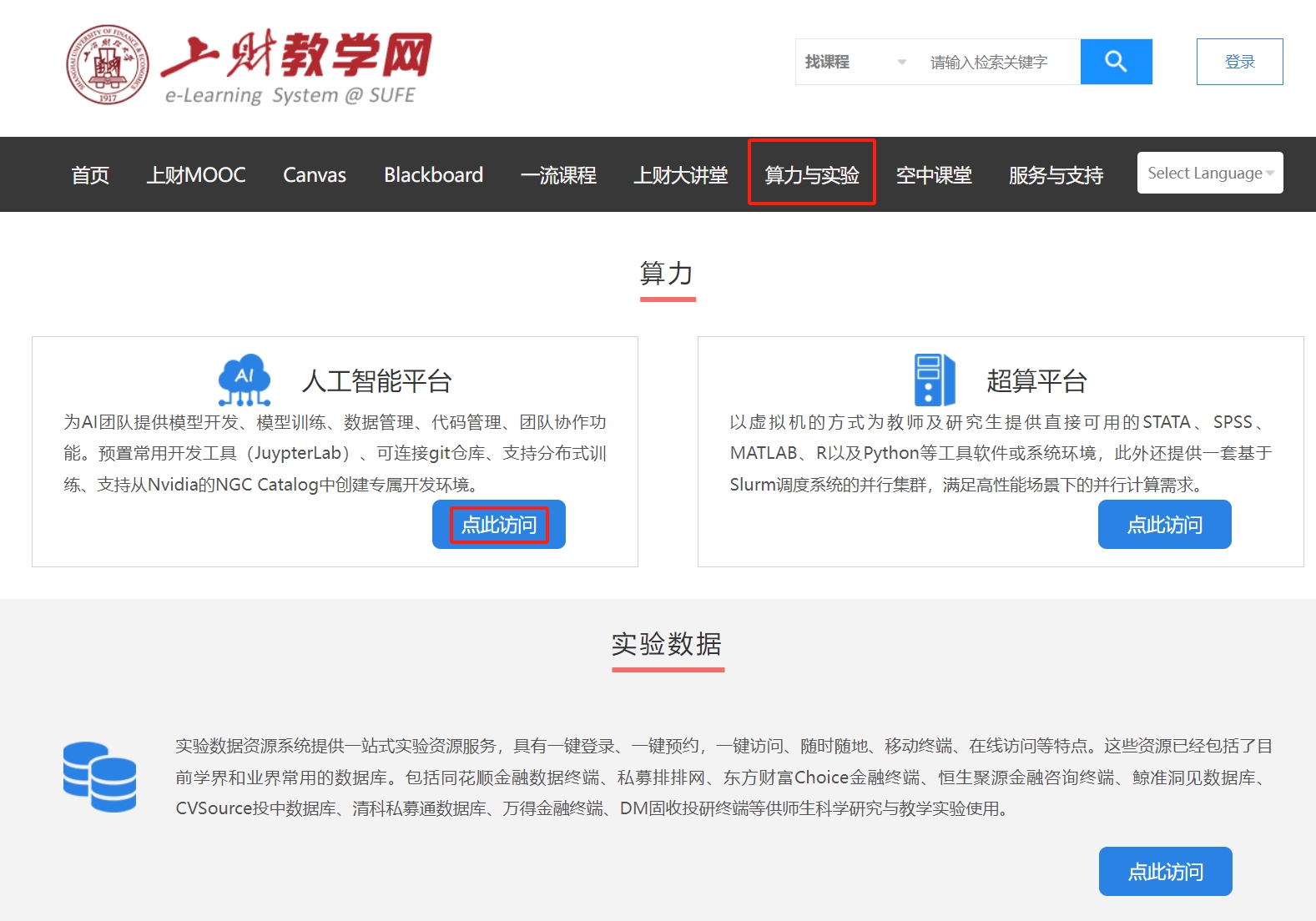
选择GPU服务申请,自动跳转到gemini平台
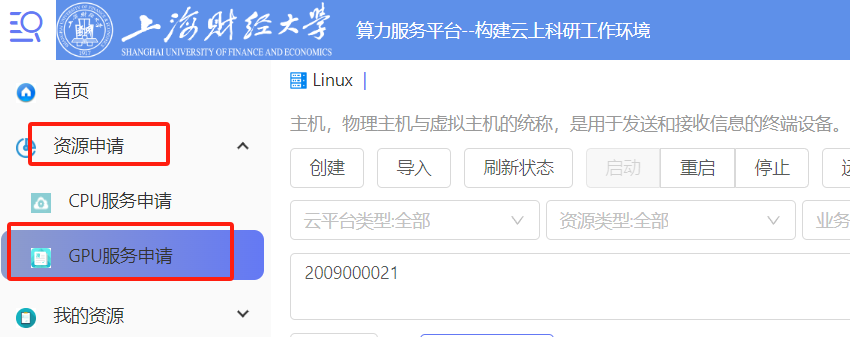
查看自己的可用资源配额
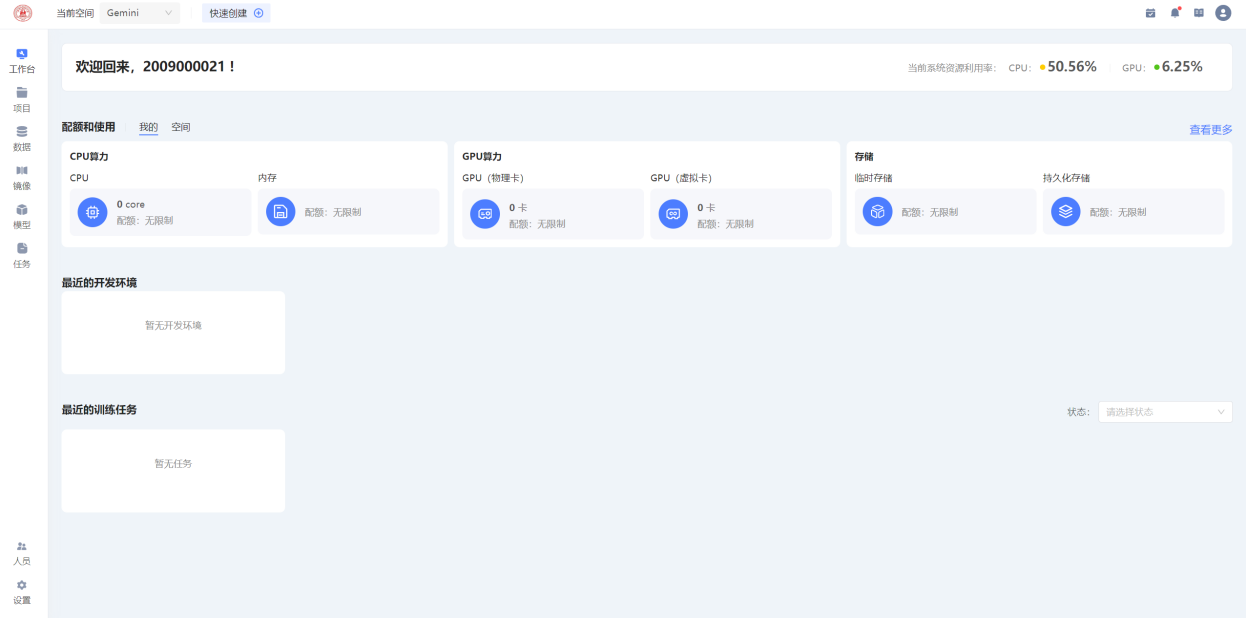
创建项目
创建DeepSeek的演示环境

镜像选择:公开镜像study:ollama_open_webui_v1
数据挂载:公开数据集 deepseek-R1模型
初始化开发环境
项目创建完成后,运行代码,进行环境初始化,环境选择虚拟GPU,选择cpu_12core-mem_64G-gpu_44G的实例
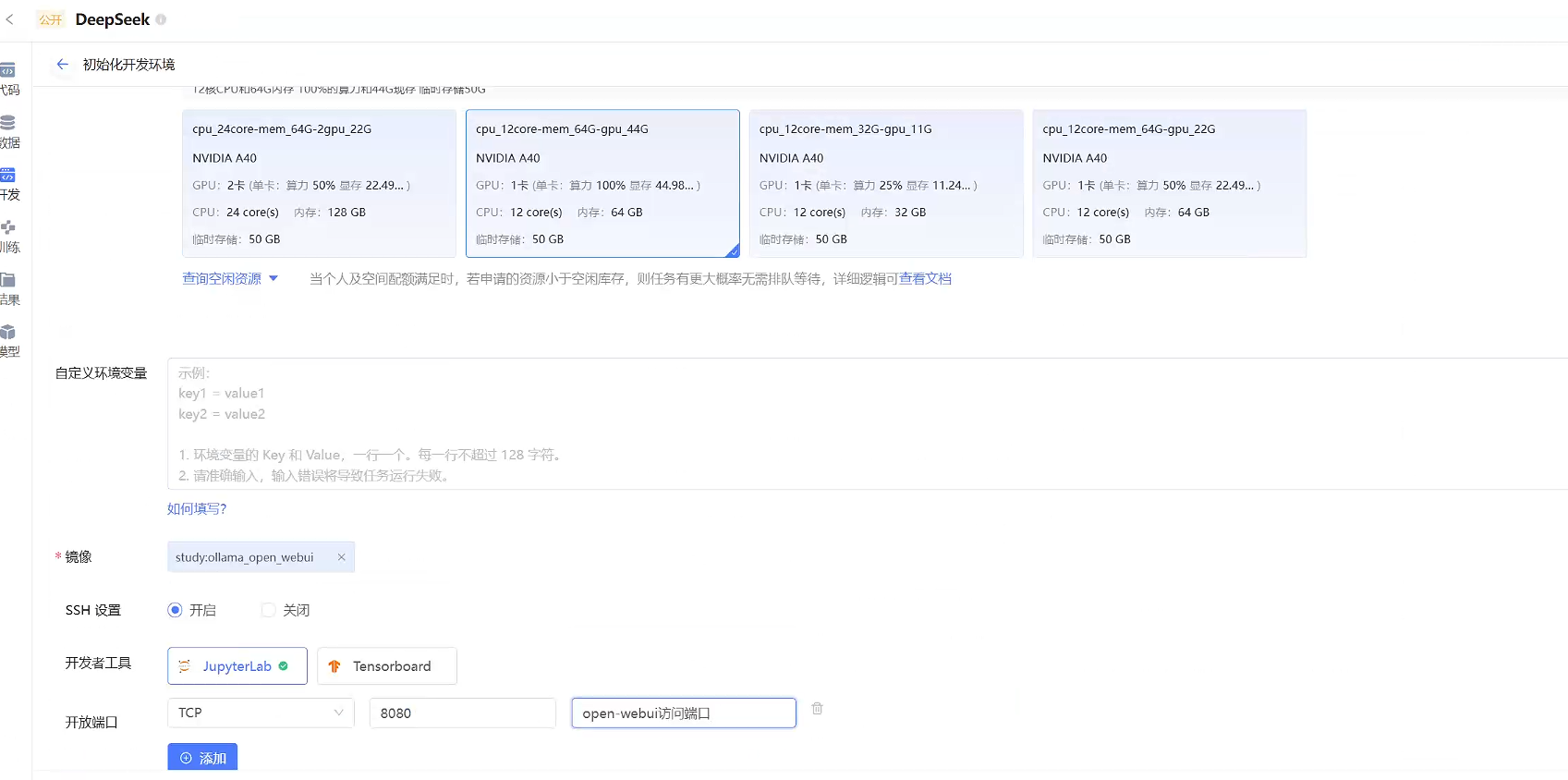
ssh设置:开启 可以用开始配置的ssh密码登录环境
开发工具: JupyterLab
开发端口:TCP 8000 用于生成Open-webui的web访问映射端口
进入开发环境
环境初始化提交后,等待平台进行资源分配,当环境变成运行中,表示环境完成启动。如果遇到启动失败,可能是网络连不上github导致,可以再次启动项目

进入开发环境,使用jupyter的Terminal命令行工具,启动ollama server服务cd /root目录,执行bash start-ollama.sh。等待5分钟后ollama serve服务启动。

cd /root
bash start-ollama.sh
查看启动日志,是否启动成功,如果出下一下内容,说明成功了。
(base) root@65bfd1318f79d8f08505f710b9918acd-taskrole1-0:~# cat nohup.out
2025/02/25 11:45:42 routes.go:1186: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:true OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:1h0m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:2h0m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/gemini/data-1 OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2025-02-25T11:45:42.262+08:00 level=INFO source=images.go:432 msg="total blobs: 13"
time=2025-02-25T11:45:42.266+08:00 level=INFO source=images.go:439 msg="total unused blobs removed: 0"
time=2025-02-25T11:45:42.271+08:00 level=INFO source=routes.go:1237 msg="Listening on [::]:11434 (version 0.5.11)"
time=2025-02-25T11:45:42.272+08:00 level=INFO source=gpu.go:217 msg="looking for compatible GPUs"
time=2025-02-25T11:45:43.653+08:00 level=INFO source=types.go:130 msg="inference compute" id=GPU-00000000-0000-000a-02aa-6c26e8000000 library=cuda variant=v12 compute=8.6 driver=12.4 name="NVIDIA A40" total="44.8 GiB" available="44.8 GiB"
[GIN] 2025/02/25 - 11:45:50 | 200 | 133.196µs | 127.0.0.1 | HEAD "/"
[GIN] 2025/02/25 - 11:45:50 | 200 | 8.963715ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/02/25 - 11:50:05 | 200 | 110.721µs | 127.0.0.1 | HEAD "/"
[GIN] 2025/02/25 - 11:50:05 | 200 | 17.691428ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/02/25 - 11:51:10 | 200 | 79.232µs | 127.0.0.1 | HEAD "/"
[GIN] 2025/02/25 - 11:51:10 | 200 | 50.74618ms | 127.0.0.1 | POST "/api/show"
time=2025-02-25T11:51:11.087+08:00 level=INFO source=sched.go:714 msg="new model will fit in available VRAM in single GPU, loading" model=/gemini/data-1/blobs/sha256-6150cb382311b69f09cc0f9a1b69fc029cbd742b66bb8ec531aa5ecf5c613e93 gpu=GPU-00000000-0000-000a-02aa-6c26e8000000 parallel=4 available=48149561344 required="21.5 GiB"
time=2025-02-25T11:51:11.355+08:00 level=INFO source=server.go:100 msg="system memory" total="881.5 GiB" free="768.0 GiB" free_swap="0 B"
time=2025-02-25T11:51:11.618+08:00 level=INFO source=memory.go:356 msg="offload to cuda" layers.requested=-1 layers.model=65 layers.offload=65 layers.split="" memory.available="[44.8 GiB]" memory.gpu_overhead="0 B" memory.required.full="21.5 GiB" memory.required.partial="21.5 GiB" memory.required.kv="2.0 GiB" memory.required.allocations="[21.5 GiB]" memory.weights.total="19.5 GiB" memory.weights.repeating="18.9 GiB" memory.weights.nonrepeating="609.1 MiB" memory.graph.full="676.0 MiB" memory.graph.partial="916.1 MiB"
time=2025-02-25T11:51:11.618+08:00 level=INFO source=server.go:185 msg="enabling flash attention"
time=2025-02-25T11:51:11.618+08:00 level=WARN source=server.go:193 msg="kv cache type not supported by model" type=""
time=2025-02-25T11:51:11.619+08:00 level=INFO source=server.go:380 msg="starting llama server" cmd="/usr/bin/ollama runner --model /gemini/data-1/blobs/sha256-6150cb382311b69f09cc0f9a1b69fc029cbd742b66bb8ec531aa5ecf5c613e93 --ctx-size 8192 --batch-size 512 --n-gpu-layers 65 --threads 48 --flash-attn --parallel 4 --port 43511"
time=2025-02-25T11:51:11.621+08:00 level=INFO source=sched.go:449 msg="loaded runners" count=1
time=2025-02-25T11:51:11.621+08:00 level=INFO source=server.go:557 msg="waiting for llama runner to start responding"
time=2025-02-25T11:51:11.622+08:00 level=INFO source=server.go:591 msg="waiting for server to become available" status="llm server error"
time=2025-02-25T11:51:11.727+08:00 level=INFO source=runner.go:936 msg="starting go runner"
time=2025-02-25T11:51:11.728+08:00 level=INFO source=runner.go:937 msg=system info="CPU : LLAMAFILE = 1 | CPU : LLAMAFILE = 1 | cgo(gcc)" threads=48
time=2025-02-25T11:51:11.728+08:00 level=INFO source=runner.go:995 msg="Server listening on 127.0.0.1:43511"
time=2025-02-25T11:51:11.875+08:00 level=INFO source=server.go:591 msg="waiting for server to become available" status="llm server loading model"
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA A40, compute capability 8.6, VMM: yes
load_backend: loaded CUDA backend from /usr/lib/ollama/cuda_v12/libggml-cuda.so
load_backend: loaded CPU backend from /usr/lib/ollama/libggml-cpu-skylakex.so
llama_load_model_from_file: using device CUDA0 (NVIDIA A40) - 45919 MiB free
llama_model_loader: loaded meta data with 26 key-value pairs and 771 tensors from /gemini/data-1/blobs/sha256-6150cb382311b69f09cc0f9a1b69fc029cbd742b66bb8ec531aa5ecf5c613e93 (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen2
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = DeepSeek R1 Distill Qwen 32B
llama_model_loader: - kv 3: general.basename str = DeepSeek-R1-Distill-Qwen
llama_model_loader: - kv 4: general.size_label str = 32B
llama_model_loader: - kv 5: qwen2.block_count u32 = 64
llama_model_loader: - kv 6: qwen2.context_length u32 = 131072
llama_model_loader: - kv 7: qwen2.embedding_length u32 = 5120
llama_model_loader: - kv 8: qwen2.feed_forward_length u32 = 27648
llama_model_loader: - kv 9: qwen2.attention.head_count u32 = 40
llama_model_loader: - kv 10: qwen2.attention.head_count_kv u32 = 8
llama_model_loader: - kv 11: qwen2.rope.freq_base f32 = 1000000.000000
llama_model_loader: - kv 12: qwen2.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 13: general.file_type u32 = 15
llama_model_loader: - kv 14: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 15: tokenizer.ggml.pre str = deepseek-r1-qwen
llama_model_loader: - kv 16: tokenizer.ggml.tokens arr[str,152064] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 17: tokenizer.ggml.token_type arr[i32,152064] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 18: tokenizer.ggml.merges arr[str,151387] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
llama_model_loader: - kv 19: tokenizer.ggml.bos_token_id u32 = 151646
llama_model_loader: - kv 20: tokenizer.ggml.eos_token_id u32 = 151643
llama_model_loader: - kv 21: tokenizer.ggml.padding_token_id u32 = 151643
llama_model_loader: - kv 22: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 23: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 24: tokenizer.chat_template str = {% if not add_generation_prompt is de...
llama_model_loader: - kv 25: general.quantization_version u32 = 2
llama_model_loader: - type f32: 321 tensors
llama_model_loader: - type q4_K: 385 tensors
llama_model_loader: - type q6_K: 65 tensors
llm_load_vocab: missing or unrecognized pre-tokenizer type, using: 'default'
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
llm_load_vocab: special tokens cache size = 22
llm_load_vocab: token to piece cache size = 0.9310 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = qwen2
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 152064
llm_load_print_meta: n_merges = 151387
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 131072
llm_load_print_meta: n_embd = 5120
llm_load_print_meta: n_layer = 64
llm_load_print_meta: n_head = 40
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 5
llm_load_print_meta: n_embd_k_gqa = 1024
llm_load_print_meta: n_embd_v_gqa = 1024
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 27648
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 2
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 1000000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 131072
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = 32B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 32.76 B
llm_load_print_meta: model size = 18.48 GiB (4.85 BPW)
llm_load_print_meta: general.name = DeepSeek R1 Distill Qwen 32B
llm_load_print_meta: BOS token = 151646 '<|begin▁of▁sentence|>'
llm_load_print_meta: EOS token = 151643 '<|end▁of▁sentence|>'
llm_load_print_meta: EOT token = 151643 '<|end▁of▁sentence|>'
llm_load_print_meta: PAD token = 151643 '<|end▁of▁sentence|>'
llm_load_print_meta: LF token = 148848 'ÄĬ'
llm_load_print_meta: FIM PRE token = 151659 '<|fim_prefix|>'
llm_load_print_meta: FIM SUF token = 151661 '<|fim_suffix|>'
llm_load_print_meta: FIM MID token = 151660 '<|fim_middle|>'
llm_load_print_meta: FIM PAD token = 151662 '<|fim_pad|>'
llm_load_print_meta: FIM REP token = 151663 '<|repo_name|>'
llm_load_print_meta: FIM SEP token = 151664 '<|file_sep|>'
llm_load_print_meta: EOG token = 151643 '<|end▁of▁sentence|>'
llm_load_print_meta: EOG token = 151662 '<|fim_pad|>'
llm_load_print_meta: EOG token = 151663 '<|repo_name|>'
llm_load_print_meta: EOG token = 151664 '<|file_sep|>'
llm_load_print_meta: max token length = 256
llm_load_tensors: offloading 64 repeating layers to GPU
llm_load_tensors: offloading output layer to GPU
llm_load_tensors: offloaded 65/65 layers to GPU
llm_load_tensors: CUDA0 model buffer size = 18508.35 MiB
llm_load_tensors: CPU_Mapped model buffer size = 417.66 MiB
llama_new_context_with_model: n_seq_max = 4
llama_new_context_with_model: n_ctx = 8192
llama_new_context_with_model: n_ctx_per_seq = 2048
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 1
llama_new_context_with_model: freq_base = 1000000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: n_ctx_per_seq (2048) < n_ctx_train (131072) -- the full capacity of the model will not be utilized
llama_kv_cache_init: kv_size = 8192, offload = 1, type_k = 'f16', type_v = 'f16', n_layer = 64, can_shift = 1
llama_kv_cache_init: CUDA0 KV buffer size = 2048.00 MiB
llama_new_context_with_model: KV self size = 2048.00 MiB, K (f16): 1024.00 MiB, V (f16): 1024.00 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 2.40 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 307.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 26.01 MiB
llama_new_context_with_model: graph nodes = 1991
llama_new_context_with_model: graph splits = 2
time=2025-02-25T11:51:20.424+08:00 level=INFO source=server.go:596 msg="llama runner started in 8.80 seconds"
[GIN] 2025/02/25 - 11:51:20 | 200 | 9.967324642s | 127.0.0.1 | POST "/api/generate"
[GIN] 2025/02/25 - 11:51:54 | 200 | 45.102µs | 127.0.0.1 | HEAD "/"
[GIN] 2025/02/25 - 11:51:54 | 200 | 23.106739ms | 127.0.0.1 | POST "/api/show"
[GIN] 2025/02/25 - 11:51:54 | 200 | 42.649001ms | 127.0.0.1 | POST "/api/generate"
[GIN] 2025/02/25 - 11:52:16 | 200 | 1.928307256s | 127.0.0.1 | POST "/api/chat"
[GIN] 2025/02/25 - 11:52:27 | 200 | 74.689µs | 127.0.0.1 | HEAD "/"
[GIN] 2025/02/25 - 11:52:27 | 200 | 40.634335ms | 127.0.0.1 | POST "/api/show"
[GIN] 2025/02/25 - 11:52:28 | 200 | 42.151549ms | 127.0.0.1 | POST "/api/generate"
[GIN] 2025/02/25 - 11:52:39 | 200 | 1.679791286s | 127.0.0.1 | POST "/api/chat"
Usage: open-webui serve [OPTIONS]
Try 'open-webui serve --help' for help.
╭─ Error ──────────────────────────────────────────────────────────────────────╮
│ Got unexpected extra argument (open-webui.log) │
╰──────────────────────────────────────────────────────────────────────────────╯
[GIN] 2025/02/25 - 12:03:57 | 200 | 16.620593ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/02/25 - 12:03:57 | 200 | 189.64µs | 127.0.0.1 | GET "/api/version"
[GIN] 2025/02/25 - 12:04:23 | 200 | 5.90623ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/02/25 - 12:04:38 | 200 | 4.997825ms | 127.0.0.1 | GET "/api/tags"
也可以用一下命令查看运行的DeepSeek模型的具体信息,参数等
(base) root@65bfd1318f79d8f08505f710b9918acd-taskrole1-0:~# ollama list
NAME ID SIZE MODIFIED
deepseek-r1:14b ea35dfe18182 9.0 GB 3 days ago
deepseek-r1:7b 0a8c26691023 4.7 GB 3 days ago
deepseek-r1:70b 0c1615a8ca32 42 GB 3 days ago
deepseek-r1:32b 38056bbcbb2d 19 GB 3 days ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 3 days ago
接下来,手动运行一个模型,比如70B
(base) root@65bfd1318f79d8f08505f710b9918acd-taskrole1-0:~# ollama run deepseek-r1:70b
>>> Send a message (/? for help)
启动openwebui工具,提供基于web的对话页面
cd /root
bash start-open-webui.sh
查看启动日志,如果看到一下信息,说明启动成功
(base) root@65bfd1318f79d8f08505f710b9918acd-taskrole1-0:~# cat open-webui.log
Loading WEBUI_SECRET_KEY from file, not provided as an environment variable.
Loading WEBUI_SECRET_KEY from /root/.webui_secret_key
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [open_webui.env] 'ENABLE_SIGNUP' loaded from the latest database entry
INFO [open_webui.env] 'DEFAULT_LOCALE' loaded from the latest database entry
INFO [open_webui.env] 'DEFAULT_PROMPT_SUGGESTIONS' loaded from the latest database entry
WARNI [open_webui.env]
WARNING: CORS_ALLOW_ORIGIN IS SET TO '*' - NOT RECOMMENDED FOR PRODUCTION DEPLOYMENTS.
INFO [open_webui.env] Embedding model set: sentence-transformers/all-MiniLM-L6-v2
WARNI [langchain_community.utils.user_agent] USER_AGENT environment variable not set, consider setting it to identify your requests.
/root/miniconda3/envs/open-webui/lib/python3.11/site-packages/open_webui
/root/miniconda3/envs/open-webui/lib/python3.11/site-packages
/root/miniconda3/envs/open-webui/lib/python3.11
Running migrations
██████╗ ██████╗ ███████╗███╗ ██╗ ██╗ ██╗███████╗██████╗ ██╗ ██╗██╗
██╔═══██╗██╔══██╗██╔════╝████╗ ██║ ██║ ██║██╔════╝██╔══██╗██║ ██║██║
██║ ██║██████╔╝█████╗ ██╔██╗ ██║ ██║ █╗ ██║█████╗ ██████╔╝██║ ██║██║
██║ ██║██╔═══╝ ██╔══╝ ██║╚██╗██║ ██║███╗██║██╔══╝ ██╔══██╗██║ ██║██║
╚██████╔╝██║ ███████╗██║ ╚████║ ╚███╔███╔╝███████╗██████╔╝╚██████╔╝██║
╚═════╝ ╚═╝ ╚══════╝╚═╝ ╚═══╝ ╚══╝╚══╝ ╚══════╝╚═════╝ ╚═════╝ ╚═╝
v0.5.16 - building the best open-source AI user interface.
https://github.com/open-webui/open-webui
Fetching 30 files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:00<00:00, 2465.06it/s]
INFO: Started server process [189]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
web页面访问需要基于外部端口进行访问 40287 是截图位置显示的外部端口,然后通过本地的浏览器访问(此ip地址和端口,每个人的不一样),即可打开web界面
注意:每个人的IP和端口是不同的,根据自己的环境来修改
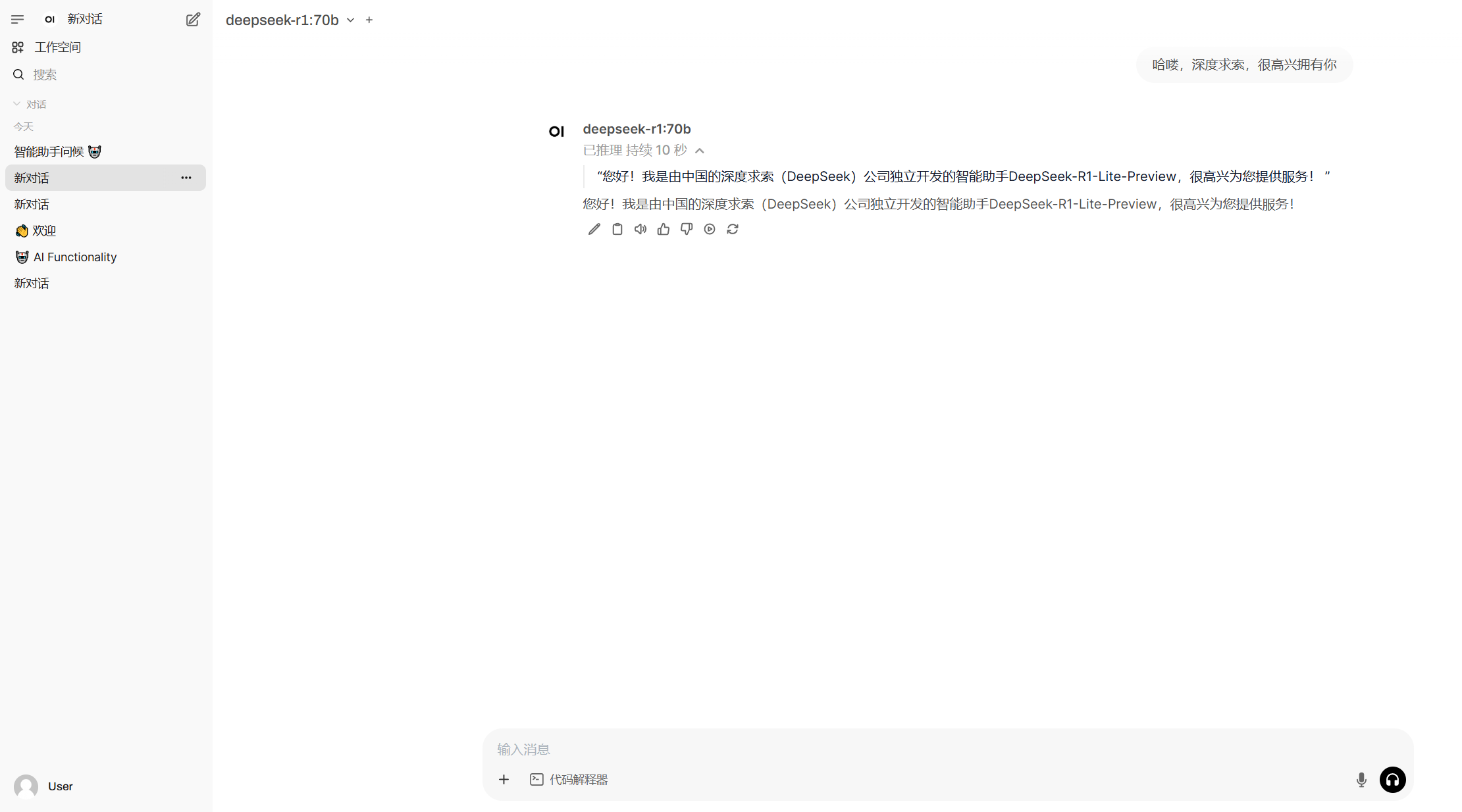
备注:由于现场配置了GPU的超时时长,10分钟左右如果没有使用模型,ollama服务会自定停止,现象是截图位置没有模型可供选择,此时,需要重新启动ollama serve服务。
彩蛋来啦
上海财经大学DeepSeek-R1 671B版(限时免费)
需要API访问的,可以邮件申请:huangjie@sufe.edu.cn